Linux 5.11 内存管理
声明
代码块的开头一般都标有代码的相对路径,根目录为源代码根目录
笔者尽可能会在代码块中每一行代码的上方进行注释,然后在代码块的下方总结该函数的行为
关键词 下面是本文和代码可能会用到的一些关键词,防止读者(自己)混淆
页:一般指一页物理页,大小一般为 4 KB
页面:由一页或者多个连续页组成的内存区,为 Buddy System 的最小管理单位
partial page/slab:有空闲对象的页面
cpu slab:kmem_cache_cpu->page 指向的 slab
cpu partial slab:kmem_cache_cpu->partial 指向的 partial slab
node slab:kmem_cache_node->partial 指向的 partial slab
struct page new:保存 page 新状态,更新 page 状态时使用struct page old:保存 page 旧状态,用于原子操作时保证单线程修改变量,防止条件竞争
一般用于更新 page->freelist 和 page->counters
有些代码可能会直接定义 freelist 或 prior 和 counters 变量来保存状态,作用都是一样的
cmpxchg 宏:一类原子操作的宏,用于防止条件竞争,会将值先与保存的原值进行比较,相等后再赋新值,如 this_cpu_cmpxchg(pcp, oval, nval) 相当于 if(pcp == oval) pcp = nval
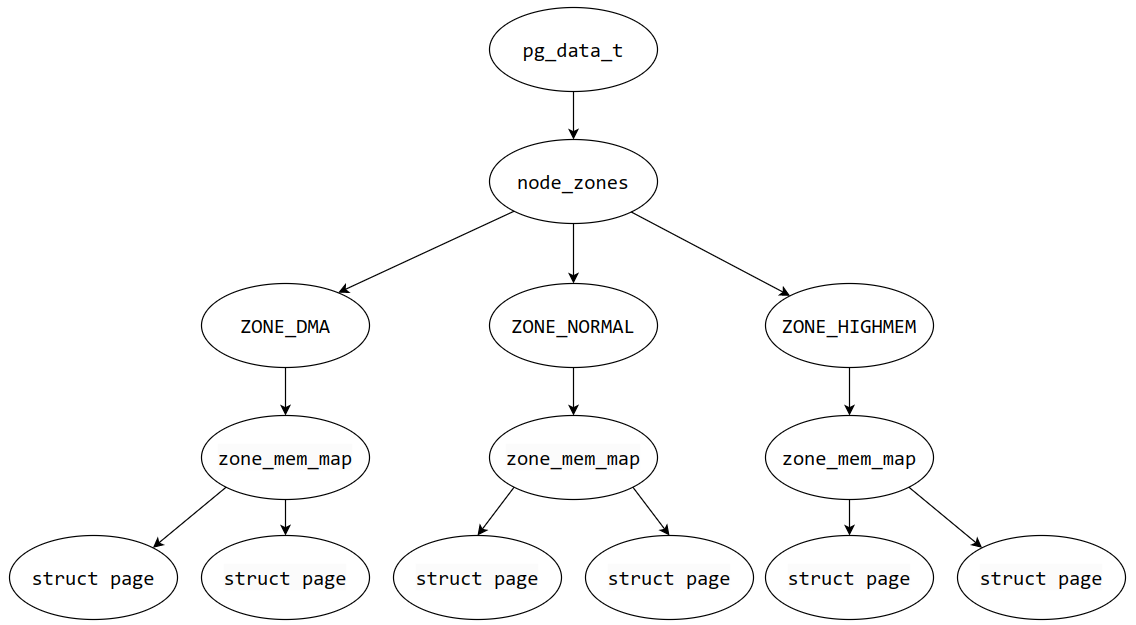
物理内存 Linux 使用三级结构对物理内存进行管理
Page
页
物理内存最小的管理单元,也是虚拟内存映射到物理内存的最小单位
Zone
Node
Page Linux 使用 page 结构体来管理一个页,一般一页为 4KB
结构体的内容如下(结构体的定义在 include/linux/mm_types.h 中,这里就不把代码放出来凑字数了)
flags
union1
5 个字长
这个 union 根据 page 的不同用途,定义不同的结构体,节省内存
union2
_refcount
其他扩展
下面介绍比较重要的字段
flags标志位,每一位表示一种状态,状态 enum pageflags 在 include/linux/page-flags.h 中定义
PG_locked
PG_referenced
该页刚被访问过,与 PG_reclaim 用于匿名与文件备份缓存的页面回收
PG_reclaim
PG_uptodate
最新状态(up-to-date),该页被读后会变更为最新状态
PG_dirty
PG_lru
PG_active
PG_workingset
该页位于某个进程的工作集(working set,在某一时刻被使用的内存页)中
PG_waiters
PG_error
PG_slab
PG_owner_priv_1
该页由其所有者使用,若是作为 pagecache 页面,则可能是被文件系统使用
PG_arch_1
PG_reserved
该页被保留,不能够被 swap out(内核会将不活跃的页交换到磁盘上)
PG_private && PG_private2
PG_writeback
PG_head
该页是复合页(compound pages)的第一个页
PG_mappedtodisk
PG_swapbacked
PG_unevictable
该页不可被回收(被锁),且会出现在 LRU_UNEVICTABLE 链表中
PG_mlocked
该页被对应的 vma 上锁(通常是系统调用 mlock)
PG_uncached
PG_hwpoison
PG_arch_2:64位下的体系结构相关标志位
_mapcount 该字段在 union2 中
1 2 3 4 5 6 union { atomic_t _mapcount; unsigned int page_type; unsigned int active; int units; };
映射计数,该页被页表映射的次数,可以理解为有多少个进程共享这一页
_refcount引用计数,该页在某一个时刻被引用的个数
内核使用 get_page 函数增加引用计数,put_page 函数减少引用计数,当引用计数为 0 时,会调用 __put_single_page 释放该页
virtual该页在内核 中被映射的虚拟地址
基础内存模型 Linux 定义了三种内存模型,定义在 include/asm-generic/memory_model.h 中
#todo 做一张内存模型的图
Flat Memory 平滑内存模型,顾名思义,所有的物理内存地址连续,一个 page 数组 mem_map 全局变量来表示对应的所有物理内存
Discontiguous Memory 非连续内存模型,顾名思义,物理内存地址不完全连续,内存之间存在空洞(hole)
每一段连续物理内存由 pglist_data 结构体表示,结构体中 node_mem_map 字段为一个 page 数组,该数组对应这一段连续物理内存
再往上一层,有一个 pglist_data 指针数组 node_data 全局变量来存放每个 pglist_data 的地址
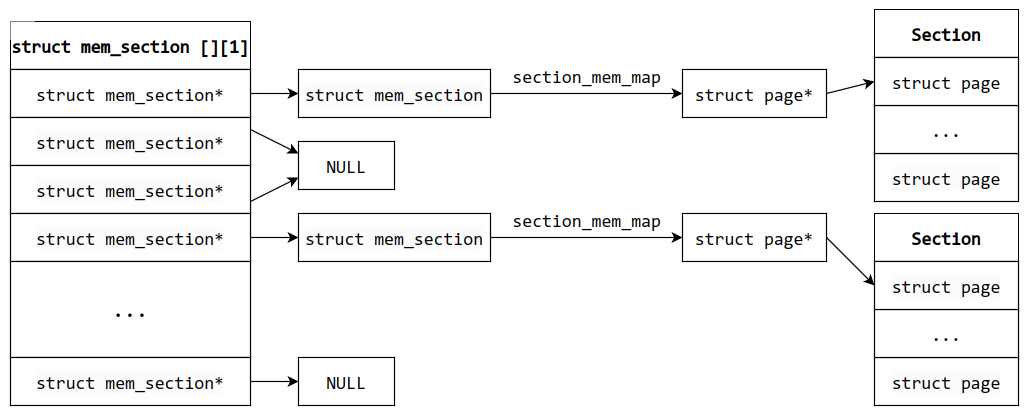
Sparse Memory 离散内存模型,该内存模型相当于可热插拔 的非连续内存模型,是最常用的基础内存模型
物理内存以 section (节)为单位进行管理,每一段连续物理内存由 mem_section 结构体中的 section_mem_map 对应
section_mem_map 本身是一个 unsigned long 变量,可以通过 section_mem_map & SECTION_MAP_MASK 来获取对应的 section 首地址,内核中用 __section_mem_map_addr 函数表示这一操作
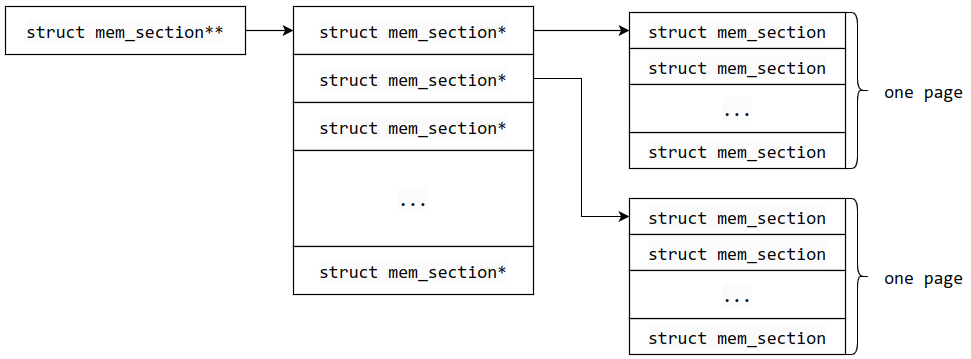
再往上一层,有一个 mem_section 二维数组 mem_section(同名)存放每个 mem_section 的实体或地址,这个二维数组大小可以是固定的,也可以是动态的(struct mem_section **mem_section,一般在 section 比较多的情况下需要开启 CONFIG_SPARSEMEM_EXTREME),指针可能为空
mm/sparse.c 1 2 3 4 5 6 7 8 9 10 11 12 #ifdef CONFIG_SPARSEMEM_EXTREME struct mem_section **mem_section ;#else struct mem_section mem_section [NR_SECTION_ROOTS ][SECTIONS_PER_ROOT ] ____cacheline_internodealigned_in_smp ; #endif #ifdef CONFIG_SPARSEMEM_EXTREME #define SECTIONS_PER_ROOT (PAGE_SIZE / sizeof (struct mem_section)) #else #define SECTIONS_PER_ROOT 1 #endif
固定和动态大小的二维数组 mem_section 布局是不同的
固定大小的 mem_section 实际上是一个一维指针数组
第二维的大小 SECTIONS_PER_ROOT 为 1
动态大小的 mem_section 是实实在在的二维数组
第二维的大小 SECTIONS_PER_ROOT,即一页所能存放的 mem_section 结构体的个数
也就是说,mem_section 会连续存储在一页中,并且有多个页来存储 mem_section,也表明 section 数量也确实多
下图为固定大小的 mem_section
下面是动态大小的 mem_section
PFN 与 page 地址的转换 在内核中常会用到 PFN(页帧号 Page Frame Number) 来简单表示一个页(而不是用复杂的 page 指针地址表示),可以理解为该页在物理内存的位置号,使用上会涉及到 PFN 与 page 地址之间的转换 __page_to_pfn 和 __pfn_to_page
这里只讲 Sparse Memory 的转换,宏定义位于 include/linux/memory_model 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #elif defined(CONFIG_SPARSEMEM) #define __page_to_pfn(pg) \ ({ const struct page *__pg = (pg); \ int __sec = page_to_section(__pg); \ (unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \ }) #define __pfn_to_page(pfn) \ ({ unsigned long __pfn = (pfn); \ struct mem_section *__sec = __pfn_to_section(__pfn); \ __section_mem_map_addr(__sec) + __pfn; \ }) #endif
注意 mem_section 的 section_mem_map 是等于该 section 第一个 page 的地址减去 section 第一个 page 对应的页在物理内存中的位置号 start_pfn
由此可以得到下面的公式
$$
page 地址 -> PFN首先使用 page_to_section 通过 page 的 flags 字段该页所属 section 号
include/linux/mm.h 1 2 3 4 static inline unsigned long page_to_section (const struct page *page) { return (page->flags >> SECTIONS_PGSHIFT) & SECTIONS_MASK; }
然后使用 __nr_to_section 获取对应的 mem_section 结构体地址
include/linux/mmzone.h 1 2 3 4 5 6 7 8 9 10 11 12 static inline struct mem_section *__nr_to_section (unsigned long nr ){ #ifdef CONFIG_SPARSEMEM_EXTREME if (!mem_section) return NULL ; #endif if (!mem_section[SECTION_NR_TO_ROOT(nr)]) return NULL ; return &mem_section[SECTION_NR_TO_ROOT(nr)][nr & SECTION_ROOT_MASK]; } #define SECTION_NR_TO_ROOT(sec) ((sec) / SECTIONS_PER_ROOT)
SECTION_NR_TO_ROOT 是计算该 section 在二维数组的第一个下标,与 SECTION_ROOT_MASK 做与运算,获取在二维数组的第二个下标
然后使用 __section_mem_map_addr 获取 page 所在 section 的 section_mem_map
include/linux/mmzone.h 1 2 3 4 5 6 7 static inline struct page *__section_mem_map_addr (struct mem_section *section ){ unsigned long map = section->section_mem_map; map &= SECTION_MAP_MASK; return (struct page *)map ; }
最后作差即可得到 PFN
PFN -> page 地址 先通过 __pfn_to_section 将 pfn 转换成对应的 section
include/linux/mmzone.h 1 2 3 4 5 6 7 8 9 static inline struct mem_section *__pfn_to_section (unsigned long pfn ){ return __nr_to_section(pfn_to_section_nr(pfn)); } static inline unsigned long pfn_to_section_nr (unsigned long pfn) { return pfn >> PFN_SECTION_SHIFT; }
其中会调用 pfn_to_section_nr 获取所属 section 号,再通过 __nr_to_section 获取 mem_section 地址
然后使用 __section_mem_map_addr 获取 page 所在 section 的 section_mem_map
最后相加即可得到 page 地址
Sparse Memory Virtual Memmap 这是 Linux 最常用的内存模型之一
开启虚拟地址空间到物理地址空间的映射,虚拟地址空间的所有页都是连续的,所有的 page 都抽象到一个虚拟数组 vmemmap 中,PFN 也就代表着该页在虚拟空间的位置
include/asm-generic/memory_model.h 1 2 #define __pfn_to_page(pfn) (vmemmap + (pfn)) #define __page_to_pfn(page) (unsigned long)((page) - vmemmap)
使用简单的加减法即可互相转换
Zone Linux 使用区 来管理一段内存页,使用 zone 结构体表示,结构体定义位于 include/linux/mmzone.h
区根据地址不同分为不同的区
ZONE_DMA
ZONE_DMA32
ZONE_NORMAL
x86:16 - 896 MB
x86_64:4 GB+
ZONE_HIGHMEM
下面介绍比较重要的字段
_watermark1 unsigned long _watermark[NR_WMARK];
水位线,每个区从高到低有三档水位线:WMARK_HIGH、WMARK_LOW、WMARK_MIN
Buddy System 会根据空闲内存和水位线比较判断当前的内存情况,进行内存回收
zone_pgdat1 struct pglist_data *zone_pgdat ;
指向 zone 所属的节点
pageset1 struct per_cpu_pageset __percpu *pageset ;
多 CPU 的引入会导致条件竞争,其中一个解决办法是锁,但是频繁的加解锁和等待时间造成巨大的开销,因此引入 per_cpu_pageset 结构体,为每一个 CPU 单独准备一个页面仓库 pageset,即每个 CPU 的 pageset 指针指向不同的实体
Buddy System 初始化时会将页面均匀地放在各个 CPU 的 pageset 中,分配时优先从自己的 pageset 中分配
include/linux/mmzone.h 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct per_cpu_pageset { struct per_cpu_pages pcp ; #ifdef CONFIG_NUMA s8 expire; u16 vm_numa_stat_diff[NR_VM_NUMA_STAT_ITEMS]; #endif #ifdef CONFIG_SMP s8 stat_threshold; s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS]; #endif }; struct per_cpu_pages { int count; int high; int batch; struct list_head lists [MIGRATE_PCPTYPES ]; };
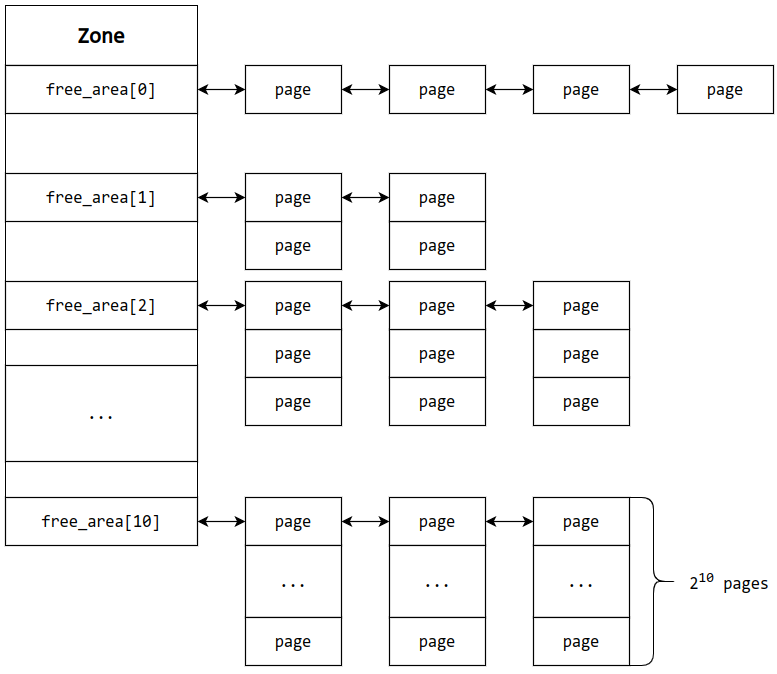
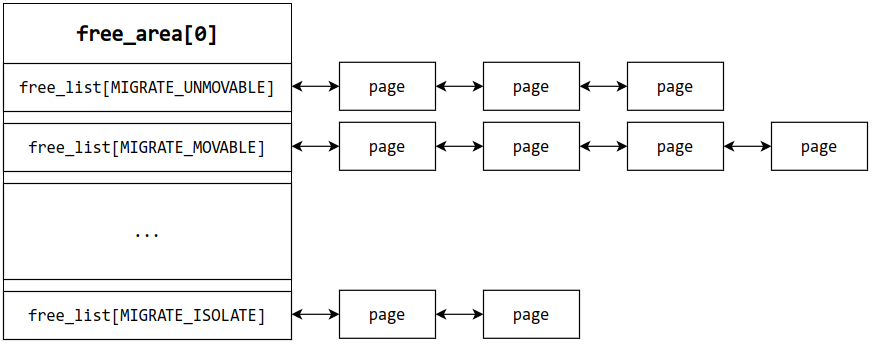
free_area1 struct free_area free_area [MAX_ORDER ];
存放 Buddy System 分阶管理的页面,页面以双向链表形式连接
Node Linux 使用节点 来管理几个内存区,使用 pglist_data 结构体表示,结构体定义位于 include/linux/mmzone.h
使用内存控制器来划分节点,同一内存控制器下的 CPU 对应的节点内存为本地内存
大部分计算机只有一个 Node
#todo
Buddy System 内存组织形式 在 Buddy System 中,按照空闲页面的大小进行分阶(order)管理,第 n 阶就是 2 的 n 次方个页的大小,存储在 zone 的 free_area 中,页面 为 Buddy System 的最小管理单位
空闲页面以双向链表的形式进行连接
1 2 3 4 5 6 7 8 9 10 11 12 struct free_area free_area [MAX_ORDER ];struct free_area { struct list_head free_list [MIGRATE_TYPES ]; unsigned long nr_free; }; struct list_head { struct list_head *next , *prev ; };
free_list本质是一个双向链表,由于页面迁移机制,还要按照不同的迁移类型(migrate type)对相同大小页面进行分类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 enum migratetype { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_PCPTYPES, MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, #ifdef CONFIG_CMA MIGRATE_CMA, #endif #ifdef CONFIG_MEMORY_ISOLATION MIGRATE_ISOLATE, #endif MIGRATE_TYPES };
MIGRATE_UNMOVABLE:这类型页面在内存当中有着固定的位置,不能移动
MIGRATE_MOVABLE:这类页面可以随意移动,例如用户空间的页面,我们只需要复制数据后改变页表映射即可
MIGRATE_RECLAIMABLE:这类页面不能直接移动,但是可以删除,例如映射文件的页
MIGRATE_PCPTYPES:per_cpu_pageset,即每 CPU 页帧缓存,其迁移仅限于同一节点内
MIGRATE_CMA:Contiguous Memory Allocator,即连续的物理内存
MIGRATE_ISOLATE:不能从该链表分配页面,该链表用于跨 NUMA 节点进行页面移动,将页面移动到使用该页面最为频繁的 CPU 所处节点
MIGRATE_TYPES:表示迁移类型的数目
nr_free当前 free_area 中的空闲页面数量
页面分配 Buddy System 提供了一些用与分配页面的接口函数,它们最终都会调用核心函数 struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask)
下面围绕核心函数来介绍页面分配机制
gfp_tGFP 即 Get Free Page
核心函数的第一个参数 gfp_t 表示在分配页面时的标志位,定义位于 include/linux/gfp.h 中
内存管理区修饰符 主要描述从哪块内存区分配内存
Flag
Description
__GFP_DMA
从 ZONE_DMA 区中分配内存
__GFP_HIGNMEM
从 ZONE_HIGHMEM 区中分配内存
__GFP_DMA32
从 ZONE_DMA32 区中分配内存
__GFP_MOVABLE
内存规整时可以迁移或回收页面
移动和替换修饰符 主要描述分配的页面的迁移属性
Flag
Description
__GFP_RECLAIMABLE
分配的内存页面可以回收
__GFP_WRITE
申请的页面会被弄成脏页
__GFP_HARDWALL
强制使用 cpuset 内存分配策略
__GFP_THISNODE
在指定的节点上分配内存
__GFP_ACCOUNT
kmemcg 会记录分配过程
水位线修饰符
Flag
Description
__GFP_ATOMIC
高优先级分配内存,分配器可以分配最低警戒水位线下的预留内存
__GFP_HIGH
分配内存的过程中不可以睡眠或执行页面回收动作
__GFP_MEMALLOC
允许访问所有的内存
__GFP_NOMEMALLOC
不允许访问最低警戒水位线下的系统预留内存
回收修饰符 主要描述页面回收的相关属性
Flag
Description
__GFP_IO
启动物理 I/O 传输
__GFP_FS
允许调用底层 FS 文件系统。可避免分配器递归到可能已经持有锁的文件系统中,避免死锁
__GFP_DIRECT_RECLAIM
分配内存过程中可以使用直接内存回收
__GFP_KSWAPD_RECLAIM
内存到达低水位时唤醒 kswapd 线程异步回收内存
__GFP_RECLAIM
表示是否可以直接内存回收或者使用 kswapd 线程进行回收
__GFP_RETRY_MAYFAIL
分配内存可以可能会失败,但是在申请过程中会回收一些不必要的内存,使整个系统受益
__GFP_NOFAIL
内存分配失败后无限制的重复尝试,直到分配成功
__GFP_NORETRY
直接页面回收或者内存规整后还是无法分配内存时,不启用 retry 反复尝试分配内存,直接返回 NULL
行为修饰符 主要描述分配页面时的行为
Flag
Fescription
__GFP_NOWARN
关闭内存分配过程中的 WARNING
__GFP_COMP
分配的内存页面将被组合成复合页
__GFP_ZERO
返回一个全部填充为 0 的页面
组合类型
Flag
Element
Description
GFP_ATOMIC
__GFP_HIGH | __GFP_ATOMIC | __GFP_KSWAPD_RECLAIM
分配过程不能休眠,分配具有高优先级,可以访问系统预留内存
GFP_KERNEL
__GFP_RECLAIM | __GFP_IO | __GFP_FS
分配内存时可以被阻塞(即休眠)
GFP_KERNEL_ACCOUNT
GFP_KERNEL | __GFP_ACCOUNT
和 GFP_KERNEL 作用一样,但是分配的过程会被 kmemcg 记录
GFP_NOWAIT
__GFP_KSWAPD_RECLAIM
分配过程中不允许因直接内存回收而导致停顿
GFP_NOIO
__GFP_RECLAIM
不需要启动任何的 I/O 操作
GFP_NOFS
__GFP_RECLAIM | __GFP_IO
不会有访问任何文件系统的操作
GFP_USER
__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL
用户空间的进程分配内存
GFP_DMA
__GFP_DMA
从 ZONE_DMA 区分配内存
GFP_DMA32
__GFP_DMA32
从 ZONE_DMA32 区分配内存
GFP_HIGHUSER
GFP_USER | __GFP_HIGHMEM
用户进程分配内存,优先使用 ZONE_HIGHMEM,且这些页面不允许迁移
GFP_HIGHUSER_MOVABLE
GFP_HIGHUSER | __GFP_MOVABLE
和 GFP_HIGHUSER 类似,但是页面可以迁移
GFP_TRANSHUGE_LIGHT
GFP_HIGHUSER_MOVABLE | __GFP_COMP | __GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM
透明大页的内存分配, light 表示不进行内存压缩和回收
GFP_TRANSHUGE
GFP_TRANSHUGE_LIGHT | __GFP_DIRECT_RECLAIM
和 GFP_TRANSHUGE_LIGHT 类似,通常 khugepaged 使用该标志
常见标志和值
Flag
Value
GFP_KERNEL
0xCC0
__GFP_ZERO
0x100
alloc_context分配结构体,描述一次内存分配的上下文信息,此结构体会在核心参数中使用到
mm/internal.h 1 2 3 4 5 6 7 8 9 struct alloc_context { struct zonelist *zonelist ; nodemask_t *nodemask; struct zoneref *preferred_zoneref ; int migratetype; enum zone_type highest_zoneidx ; bool spread_dirty_pages; };
zone_list保存此次分配操作的区 的列表,实际上就是 zone 结构体的指针数组
include/linux/mmzone.h 1 2 3 4 5 6 7 8 struct zonelist { struct zoneref _zonerefs [MAX_ZONES_PER_ZONELIST + 1]; }; struct zoneref { struct zone *zone ; int zone_idx; };
preferred_zoneref表示优先进行分配的区
spread_dirty_pages表示此次分配的页面是否会被修改且需要写回
__alloc_pages_nodemask 函数该函数为核心函数,所有页面分配的 API 函数都是基于该函数的封装
函数参数
gfp_t gpf_mask:分配标志位unsigned int order:页面的阶int prederred_nid:选取的 Node 的 id,一般为该 CPU 所在 nodenodemask_t *nodemask:限制可选取的 mask,一般为 0,不会限制
mm/page_alloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 struct page *__alloc_pages_nodemask (gfp_t gfp_mask , unsigned int order , int preferred_nid , nodemask_t *nodemask ) { struct page *page ; unsigned int alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_mask; struct alloc_context ac = if (unlikely(order >= MAX_ORDER)) { WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN)); return NULL ; } gfp_mask &= gfp_allowed_mask; alloc_mask = gfp_mask; if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags)) return NULL ; alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask); page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac); if (likely(page)) goto out; alloc_mask = current_gfp_context(gfp_mask); ac.spread_dirty_pages = false ; ac.nodemask = nodemask; page = __alloc_pages_slowpath(alloc_mask, order, &ac); out: if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page && unlikely(__memcg_kmem_charge_page(page, gfp_mask, order) != 0 )) { __free_pages(page, order); page = NULL ; } trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype); return page; }
步骤主要分为三步
检查参数的合法性,做分配前的准备工作
进行快速分配 ,成功则直接返回结果
若快速分配失败,进行慢速分配
分配前的准备工作 通过调用 prepare_alloc_page 来初始化 alloc_context 结构体、获取区等
mm/page_alloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 static inline bool prepare_alloc_pages (gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_mask, unsigned int *alloc_flags) { ac->highest_zoneidx = gfp_zone(gfp_mask); ac->zonelist = node_zonelist(preferred_nid, gfp_mask); ac->nodemask = nodemask; ac->migratetype = gfp_migratetype(gfp_mask); if (cpusets_enabled()) { *alloc_mask |= __GFP_HARDWALL; if (!in_interrupt() && !ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; } fs_reclaim_acquire(gfp_mask); fs_reclaim_release(gfp_mask); might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM); if (should_fail_alloc_page(gfp_mask, order)) return false ; *alloc_flags = current_alloc_flags(gfp_mask, *alloc_flags); ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE); ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->highest_zoneidx, ac->nodemask); return true ; }
从指定的节点中一个 zone_list 作为可用区的列表
根据 cpuset 情况设置标志位
判断是否页面需要回写
取出 zone_list 第一个区作为 preferred_zoneref
快速分配:get_page_from_freelist 函数 通过 get_page_from_freelist 遍历 alloc_context 的 zone_list 中获取内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 static struct page *get_page_from_freelist (gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac) { struct zoneref *z ; struct zone *zone ; struct pglist_data *last_pgdat_dirty_limit =NULL ; bool no_fallback; retry: no_fallback = alloc_flags & ALLOC_NOFRAGMENT; z = ac->preferred_zoneref; for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx, ac->nodemask) { struct page *page ; unsigned long mark; if (cpusets_enabled() && (alloc_flags & ALLOC_CPUSET) && !__cpuset_zone_allowed(zone, gfp_mask)) continue ; if (ac->spread_dirty_pages) { if (last_pgdat_dirty_limit == zone->zone_pgdat) continue ; if (!node_dirty_ok(zone->zone_pgdat)) { last_pgdat_dirty_limit = zone->zone_pgdat; continue ; } } if (no_fallback && nr_online_nodes > 1 && zone != ac->preferred_zoneref->zone) { int local_nid; local_nid = zone_to_nid(ac->preferred_zoneref->zone); if (zone_to_nid(zone) != local_nid) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; } } mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK); if (!zone_watermark_fast(zone, order, mark, ac->highest_zoneidx, alloc_flags, gfp_mask)) { int ret; #ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT if (static_branch_unlikely(&deferred_pages)) { if (_deferred_grow_zone(zone, order)) goto try_this_zone; } #endif BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK); if (alloc_flags & ALLOC_NO_WATERMARKS) goto try_this_zone; if (node_reclaim_mode == 0 || !zone_allows_reclaim(ac->preferred_zoneref->zone, zone)) continue ; ret = node_reclaim(zone->zone_pgdat, gfp_mask, order); switch (ret) { case NODE_RECLAIM_NOSCAN: continue ; case NODE_RECLAIM_FULL: continue ; default : if (zone_watermark_ok(zone, order, mark, ac->highest_zoneidx, alloc_flags)) goto try_this_zone; continue ; } } try_this_zone: page = rmqueue(ac->preferred_zoneref->zone, zone, order, gfp_mask, alloc_flags, ac->migratetype); if (page) { prep_new_page(page, order, gfp_mask, alloc_flags); if (unlikely(order && (alloc_flags & ALLOC_HARDER))) reserve_highatomic_pageblock(page, zone, order); return page; } else { #ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT if (static_branch_unlikely(&deferred_pages)) { if (_deferred_grow_zone(zone, order)) goto try_this_zone; } #endif } } if (no_fallback) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; } return NULL ; }
从 preferred_zoneref 开始遍历 zone_list 寻找满足要求的 zone
如果开启了 cpuset,检查当前 zone 是否满足要求,若否,寻找下一个 zone
检查当前 zone 的脏页数量达到限制,若否,寻找下一个 zone
检查当前 zone 是否属于另一个 node,若是,则清除 ALLOC_NOFRAGMENT 标志,重新遍历,因为 local node 重要性大于内存碎片
检查水位线是否达标
若设置了 ALLOC_NO_WATERMARKS 忽略检查
若未达标,调用 node_reclaim 函数进行页面回收
若回收后 zone 仍不满足要求,则寻找下一个 zone
调用 rmqueue 函数,对满足要求的 zone 进行内存分配,即 Buddy System 分配算法
下面仔细看看 Buddy System 分配算法
rmqueue 函数mm/page_alloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 static inline struct page *rmqueue (struct zone *preferred_zone, struct zone *zone, unsigned int order, gfp_t gfp_flags, unsigned int alloc_flags, int migratetype) { unsigned long flags; struct page *page ; if (likely(order == 0 )) { if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA || migratetype != MIGRATE_MOVABLE) { page = rmqueue_pcplist(preferred_zone, zone, gfp_flags, migratetype, alloc_flags); goto out; } } WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1 )); spin_lock_irqsave(&zone->lock, flags); do { page = NULL ; if (order > 0 && alloc_flags & ALLOC_HARDER) { page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC); if (page) trace_mm_page_alloc_zone_locked(page, order, migratetype); } if (!page) page = __rmqueue(zone, order, migratetype, alloc_flags); } while (page && check_new_pages(page, order)); spin_unlock(&zone->lock); if (!page) goto failed; __mod_zone_freepage_state(zone, -(1 << order), get_pcppage_migratetype(page)); __count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order); zone_statistics(preferred_zone, zone); local_irq_restore(flags); out: if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) { clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags); wakeup_kswapd(zone, 0 , 0 , zone_idx(zone)); } VM_BUG_ON_PAGE(page && bad_range(zone, page), page); return page; failed: local_irq_restore(flags); return NULL ; }
对于一个页大小的页面,除了 CMA 开启且不分配 CMA 的 MIGRATE_MOVABLE 页面,都可以通过 rmqueue_pcplist 从 CPU 的内存仓库中分配
CMA 一般用于嵌入式,目的是分配一块连续的物理内存,这里不细讲
如果 order > 0 且分配优先级比较高,则调用 __rmqueue_smallest 分配
否则都调用 __rmqueue 分配内存
对页面进行检查是否是新页,不是则跳到第 2 步重新分配
rmqueue_pcplist 函数从 per_cpu_pageset 中分配 order-0(单页)页面
mm/page_alloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 static struct page *rmqueue_pcplist (struct zone *preferred_zone, struct zone *zone, gfp_t gfp_flags, int migratetype, unsigned int alloc_flags) { struct per_cpu_pages *pcp ; struct list_head *list ; struct page *page ; unsigned long flags; local_irq_save(flags); pcp = &this_cpu_ptr(zone->pageset)->pcp; list = &pcp->lists[migratetype]; page = __rmqueue_pcplist(zone, migratetype, alloc_flags, pcp, list ); if (page) { __count_zid_vm_events(PGALLOC, page_zonenum(page), 1 ); zone_statistics(preferred_zone, zone); } local_irq_restore(flags); return page; } static struct page *__rmqueue_pcplist (struct zone *zone , int migratetype , unsigned int alloc_flags , struct per_cpu_pages *pcp , struct list_head *list ) { struct page *page ; do { if (list_empty(list )) { pcp->count += rmqueue_bulk(zone, 0 , READ_ONCE(pcp->batch), list , migratetype, alloc_flags); if (unlikely(list_empty(list ))) return NULL ; } page = list_first_entry(list , struct page, lru); list_del(&page->lru); pcp->count--; } while (check_new_pcp(page)); return page; }
取出 pcplist
调用 __rmqueue_pcplist 函数分配页面
如果 pcplist 为空,调用 rmqueue_bulk 函数从当前 zone 获取若干页面加入到 pcplist 中
从 pcplist 链表中脱链,取出一个页面
返回页面
__rmqueue_smallest 函数核心函数
mm/page_alloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 static __always_inlinestruct page *__rmqueue_smallest (struct zone *zone , unsigned int order , int migratetype ) { unsigned int current_order; struct free_area *area ; struct page *page ; for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); page = get_page_from_free_area(area, migratetype); if (!page) continue ; del_page_from_free_list(page, zone, current_order); expand(zone, page, order, current_order, migratetype); set_pcppage_migratetype(page, migratetype); return page; } return NULL ; } static inline void expand (struct zone *zone, struct page *page, int low, int high, int migratetype) { unsigned long size = 1 << high; while (high > low) { high--; size >>= 1 ; VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]); if (set_page_guard(zone, &page[size], high, migratetype)) continue ; add_to_free_list(&page[size], zone, high, migratetype); set_buddy_order(&page[size], high); } }
从 zone 取出大小合适的页面,如果当前 order 的页面为空,那么从更高 order 的链表中去取
将页面脱链
调用 expand 函数将页面进行拆分和上链
从当前 order 循环到需要分配的 order
后半页面添加到对应大小的链表中
设置前半页面的 order,下一步继续拆分,直到 order 刚好合适
设置页面的迁移类型,返回页面
__rmqueue 函数mm/page_alloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 static __always_inline struct page *__rmqueue (struct zone *zone , unsigned int order , int migratetype , unsigned int alloc_flags ) { struct page *page ; if (IS_ENABLED(CONFIG_CMA)) { if (alloc_flags & ALLOC_CMA && zone_page_state(zone, NR_FREE_CMA_PAGES) > zone_page_state(zone, NR_FREE_PAGES) / 2 ) { page = __rmqueue_cma_fallback(zone, order); if (page) goto out; } } retry: page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) { if (alloc_flags & ALLOC_CMA) page = __rmqueue_cma_fallback(zone, order); if (!page && __rmqueue_fallback(zone, order, migratetype, alloc_flags)) goto retry; } out: if (page) trace_mm_page_alloc_zone_locked(page, order, migratetype); return page; }
如果开启了 CMA,从 CMA 区域获取页面(不细讲)
调用 __rmqueue_smallest 从 zone 对应迁移类型的链表中取页面
如果失败了,从 CMA 区域获取页面
如果还是失败了,调用 __rmqueue_fallback 从 zone 其他迁移类型的链表中寻找可用的页面放到当前迁移类型的链表中,重试步骤 2
如果还没有就寄
慢速分配:__alloc_pages_slowpath 函数 快速分配不成功说明系统可能没有足够的连续空闲页面,接下来进入慢速分配,先进行内存碎片整理与内存回收,再进行分配
#todo
上层 API 函数 1 2 3 4 5 6 7 8 9 10 11 12 __alloc_pages_node __alloc_pages __alloc_pages_nodemask alloc_pages alloc_pages_current __alloc_pages_nodemask __get_free_pages alloc_pages alloc_pages_current __alloc_pages_nodemask
页面释放 Buddy System 的 buddy 其实就在于页面释放时,寻找与被释放的页面内存对齐 的页面(可能与上一页面,也可能是下一页面)作为 buddy,检查该 buddy 是否可以合并
buddy 实际上就是指守护页或空闲页面
__free_one_page 是页面释放的核心函数,这里的 page 是指页面,而不是页
函数定义于 mm/page_alloc.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 static inline void __free_one_page(struct page *page, unsigned long pfn, struct zone *zone, unsigned int order, int migratetype, fpi_t fpi_flags) { struct capture_control *capc = unsigned long buddy_pfn; unsigned long combined_pfn; unsigned int max_order; struct page *buddy ; bool to_tail; max_order = min_t (unsigned int , MAX_ORDER - 1 , pageblock_order); VM_BUG_ON(!zone_is_initialized(zone)); VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page); VM_BUG_ON(migratetype == -1 ); if (likely(!is_migrate_isolate(migratetype))) __mod_zone_freepage_state(zone, 1 << order, migratetype); VM_BUG_ON_PAGE(pfn & ((1 << order) - 1 ), page); VM_BUG_ON_PAGE(bad_range(zone, page), page); continue_merging: while (order < max_order) { if (compaction_capture(capc, page, order, migratetype)) { __mod_zone_freepage_state(zone, -(1 << order), migratetype); return ; } buddy_pfn = __find_buddy_pfn(pfn, order); buddy = page + (buddy_pfn - pfn); if (!pfn_valid_within(buddy_pfn)) goto done_merging; if (!page_is_buddy(page, buddy, order)) goto done_merging; if (page_is_guard(buddy)) clear_page_guard(zone, buddy, order, migratetype); else del_page_from_free_list(buddy, zone, order); combined_pfn = buddy_pfn & pfn; page = page + (combined_pfn - pfn); pfn = combined_pfn; order++; } if (order < MAX_ORDER - 1 ) { if (unlikely(has_isolate_pageblock(zone))) { int buddy_mt; buddy_pfn = __find_buddy_pfn(pfn, order); buddy = page + (buddy_pfn - pfn); buddy_mt = get_pageblock_migratetype(buddy); if (migratetype != buddy_mt && (is_migrate_isolate(migratetype) || is_migrate_isolate(buddy_mt))) goto done_merging; } max_order = order + 1 ; goto continue_merging; } done_merging: set_buddy_order(page, order); if (fpi_flags & FPI_TO_TAIL) to_tail = true ; else if (is_shuffle_order(order)) to_tail = shuffle_pick_tail(); else to_tail = buddy_merge_likely(pfn, buddy_pfn, page, order); if (to_tail) add_to_free_list_tail(page, zone, order, migratetype); else add_to_free_list(page, zone, order, migratetype); if (!(fpi_flags & FPI_SKIP_REPORT_NOTIFY)) page_reporting_notify_free(order); }
计算 max_order 和 buddy 的 PFN
通过 page_is_buddy 检查 buddy 是否可以合并
该 buddy 是否设置 buddy 标志位或是守卫页
是否同 order
是否在同一 zone
如果可以合并,取消 buddy 标志位并脱链,或取消守卫页标志位
计算合并后的页面属性,跳转到步骤 1,继续合并,直到到达 max_order 或 buddy 不能合并
判断是否有隔离 pageblock(pageblock 是一种比较大的页面,order >= MAX_ORDER-1)
如果有则停止合并
如果没有,则跳转到步骤 1 尝试继续合并
合并完成,设置页面 order 和 buddy 标志位(表示页面为空闲页面)
判断插入到空间页面的链表头还是链表尾,通常是链表头,遵循 LIFO
上层 API 函数 1 2 3 4 5 6 free_pages __free_pages free_the_page free_unref_page or __free_pages_ok free_one_page __free_one_page
Slab Buddy System 分配的页面单位是页,而往往使用的时候并不需要那么大的空间,因此需要更细粒度的内存分配器对从 Buddy System 获取的页面进行管理,也就是 Slab Allocator,它会将页面分割成小的对象(object)供其他组件使用
Slab 又被称为内核的堆管理器,动态分配内存
Slab 经历了三个版本
Slab:最初版本,机制复杂,效率不高
Slob:用于嵌入式等的简化版本
Slub:优化后的通用版本
本文主要介绍 Slub,Linux 最常用的内存分配器
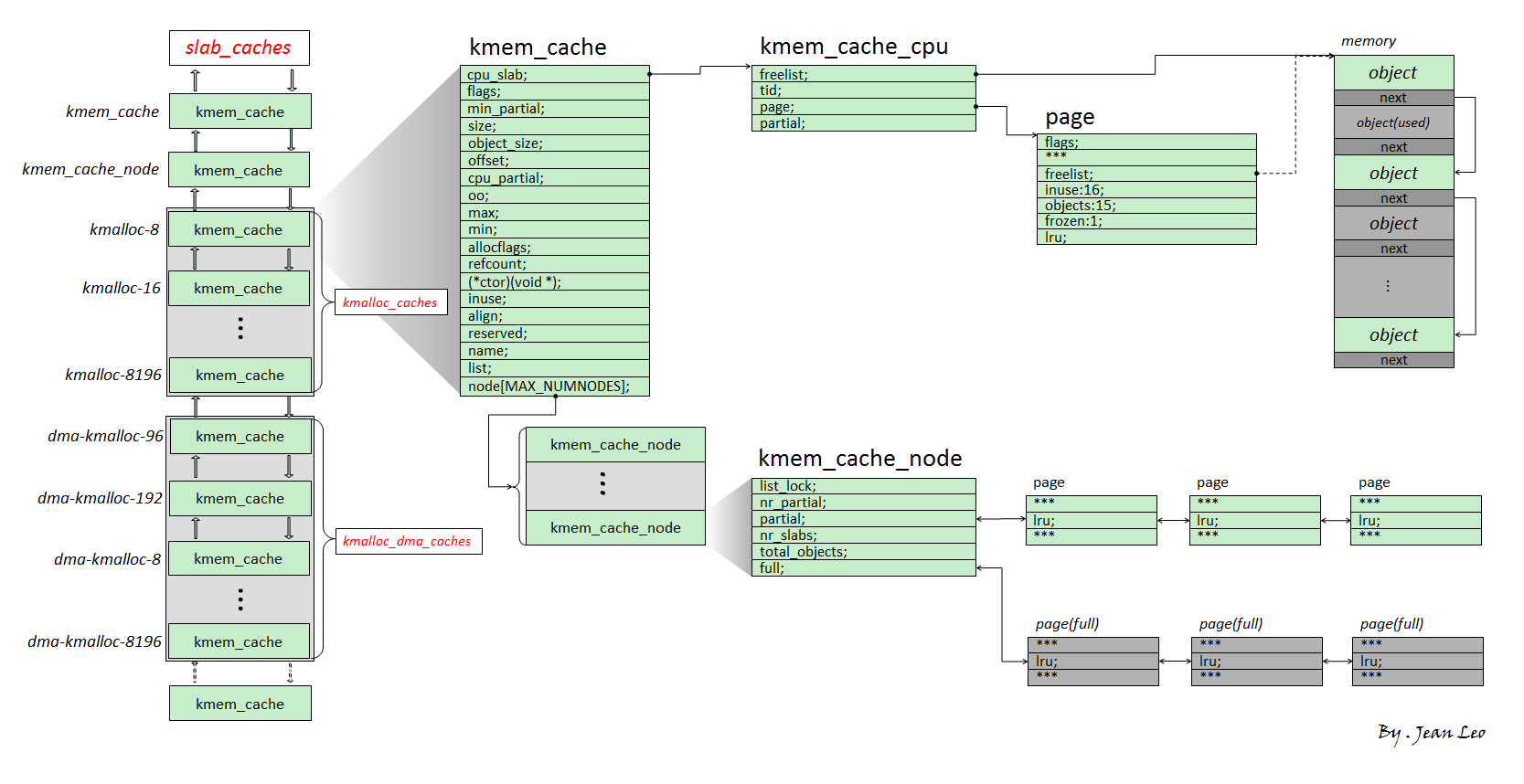
下图是 Slub 的结构概览
基本结构体 slabSlub 将从 Buddy System 获取的页面称为一张 slab,对应的匿名结构体内嵌在 page 结构体中,新版本的 Slub 是单独拿出一个 slab 结构体,本质上也是复用 page 结构体
定义位于 include/linux/mm_types.h
下面介绍与 slab 有关的几个重要字段
slab_list1 struct list_head slab_list ;
按用途连接多个 slab 的双向链表
Partial pages 1 2 3 4 5 6 7 8 9 10 struct { struct page *next ; #ifdef CONFIG_64BIT int pages; int pobjects; #else short int pages; short int pobjects; #endif };
当 slab 位于 kmem_cache_cpu 和 kmem_cache_node 的 partial 链表上会使用
next:指向链表上的下一张 slabpages:partial 链表后面的剩余页面的数量(包括自己)pobject:该 slab 上剩余空闲对象的大约数量
slab_cache1 struct kmem_cache *slab_cache ;
该 slab 的管理器,后面会详细介绍
freelist该 slab 的空闲对象单向链表,指向第一个空闲对象
counters1 2 3 4 5 6 7 8 union { unsigned long counters; struct { unsigned inuse:16 ; unsigned objects:15 ; unsigned frozen:1 ; }; };
inuse:已被使用的对象数量,包括 kmem_cache_cpu->freelist 上的空闲对象objects:对象总数frozen:是否归属于特定 CPU,cpu slab 和 cpu partial slab 都为 1
couters 和上面三个字段属于同一内存,后面有大量对 couters 的赋值操作,实际上是对 inuse & objects & frozen 的赋值
slab 分类
cpu slab:位于 kmem_cache_cpu->page 上,frozen 为 1
cpu partial slab:位于 kmem_cache_cpu->partial 链表上,frozen 为 1
node slab:位于 kmem_cache_node->partial 双向链表上
full slab:没有空闲对象的 slab,如果开启 CONFIG_SLUB_DEBUG 配置,位于 kmem_cache_node->full 双向链表上
empty slab:没有正在使用的对象的 slab
object slab 中的内存最小单元,对象
1 2 3 4 struct object { void data[]; struct object *next_free_object ; }
object 不像在 glibc 中的 chunk 有明确的结构体定义,上面的定义为笔者自己捏造的(不信就算了)
data:用于存放数据,一个 slab 上的大小相同,不同 slab 的大小可能不同next_free_object:单向链表,指向下一个空闲对象
kmem_cache用于分配特定大小或用途的对象的管理器,每个 kmem_cache 有若干张 slab
所有的 kmem_cache 存储在一个通用 kmalloc_caches 数组中,并构成一个双向链表
mm/slab_common.c 1 2 3 4 struct kmem_cache *kmalloc_caches [NR_KMALLOC_TYPES ][KMALLOC_SHIFT_HIGH + 1] __ro_after_init ={ }; EXPORT_SYMBOL(kmalloc_caches);
kmem_cache 结构体定义位于 include/linux/slub_def.h
下面介绍几个重要字段
cpu_slab1 struct kmem_cache_cpu __percpu *cpu_slab ;
percpu 变量,每个 CPU 独有一个,相当于每个 CPU 的内存池
flags标志位,用于回收等
min_partial1 unsigned long min_partial;
node partial 链表上 slab 的最小可释放数量,用于判断全是空闲对象的 slab 是放到 node slab 上还是释放给 buddy system(node slab 足够多)
size & object_size1 2 unsigned int size;unsigned int object_size;
size:对象的实际大小
object_size:对象所能存放的数据大小
offsetslab 上 next_free_object 在对象上的偏移,用于获取下一个空闲对象,不同 slab 可能不同
cpu_partial该 kmem_cache 上 cpu partial slab 上空闲对象的数量限制,用于限制 cpu partial slab 的数量
当新插入的 slab 上的空闲对象数量超过 cpu_partial,会将其他 cpu partial slab 放入 node slab
当 cpu slab 上的空闲对象数量超过 cpu_partial 的一半,不会添加 cpu partial slab
oo1 2 3 4 5 struct kmem_cache_order_objects oo ;struct kmem_cache_order_objects { unsigned int x; };
低 16 位:一张 slab 上的对象数量
高 16 位:一张 slab 的大小(order)
min1 struct kmem_cache_order_objects min ;
一张 slab 上最少的对象数量
allocflags存放 GFP 标志位
ctor对象的构造函数,分配对象会调用该函数进行初始化
inuse实际上就是 object_size
align对象对齐的宽度
random_seq1 unsigned int *random_seq;
用于在 slab 初始化或时,随机化 freelist 上空闲对象的连接顺序
useroffset & usersize1 2 unsigned int useroffset;unsigned int usersize;
Hardened Usercopy 保护相关
useroffset:用户空间能读写的区域起始偏移usersize:用户空间能读写的区域大小
node1 struct kmem_cache_node *node [MAX_NUMNODES ];
kmem_cache_node 数组,对应不同 node 的后备内存池,一般计算机只有一个
kmem_cache 类型kmem_cache 有四种类型,在进行内存分配时若未指定内存池,则会根据 allocflags 从不同的 kmem_cache 中取
include/linux/slab.h 1 2 3 4 5 6 7 8 enum kmalloc_cache_type { KMALLOC_NORMAL = 0 , KMALLOC_RECLAIM, #ifdef CONFIG_ZONE_DMA KMALLOC_DMA, #endif NR_KMALLOC_TYPES };
KMALLOC_NORMAL:通用内存池,对应 kmalloc-*,分配 flag 为 GFP_KERNELKMALLOC_RECLAIM:用于 DMA 的内存池,对应 kmalloc-dma-*KMALLOC_DMA:可以被回收的内存池,对应 kmalloc-rcl-*
若没开启 DMA 选项,则合并入 KMALLOC_NORMAL 内存池
slab alias 一种对同等/近似大小对象的 kmem_cache 进行复用的机制
当要创建一个 kmem_cache 时,若已存在能分配相等/近似大小的对象的 kmem_cache,则不会创建新的 kmem_cache,而是为原有的 kmem_cache 起一个别名,作为“新的” kmem_cache 返回
例如 Linux 4.4 以前,cred 结构体与其他大小为 192 字节的结构体,会从同一个 kmem_cache —— kmalloc-192 中分配,就很容易被 UAF 漏洞利用提权
Linux 4.4 后,开启 SLAB_ACCOUNT 后,cred 结构体属于高权限结构体,会创建一个单独的 kmem_cache —— cred_jar 单独给 cred 结构体使用,而其他普通同大小的结构体使用 kmalloc-192,彼此之间互不干扰
kmem_cache_cpu各 CPU 的独占内存池,在 kmem_cache 中为 percpu 字段
请求内存分配时,首先会尝试从当前 CPU 的 kmem_cache_cpu 取出对象
include/linux/slub_def.h 1 2 3 4 5 6 7 8 9 10 11 struct kmem_cache_cpu { void **freelist; unsigned long tid; struct page *page ; #ifdef CONFIG_SLUB_CPU_PARTIAL struct page *partial ; #endif #ifdef CONFIG_SLUB_STATS unsigned stat[NR_SLUB_STAT_ITEMS]; #endif };
freelist:指向下一个空闲对象的指针tid:表示当前处理该 kmem_cache_cpu 的线程 id,用来确保同一时刻只有一个线程在进行操作page:指向用来内存分配的页面的 slab 结构体,笔者这里简称为 cpu slabpartial:归属于该 CPU 的仍有一定空闲对象的 slab 链表,这类 slab 简称为 cpu partial slab,需要开启 CONFIG_SLUB_CPU_PARTIAL 配置
slab 上的 freelist 仅当其在 kmem_cache_cpu 的 partial 链表上有用,当 slab 在 page 上时,slab 的 freelist 为 NULL,其作用会被 kmem_cache_cpu 的 freelist 代替
#todo kmem_cache_cpu 与 slab 的联系
对象分配 slab_alloc_node上层接口最后都会调用到 slab_alloc_node 来完成内存分配
struct kmem_cache *s:当前 kmem_cachegfp_t gfpflags:分配标志位int node:指定的 node id,一般为 NUMA_NO_NODE(-1),即不指定 nodeunsigned long addr:开启 SLAB_DEBUG_FLAGS 后使用,一般不会使用
mm/slub,c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 static __always_inline void *slab_alloc_node (struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr) { void *object; struct kmem_cache_cpu *c ; struct page *page ; unsigned long tid; struct obj_cgroup *objcg =NULL ; s = slab_pre_alloc_hook(s, &objcg, 1 , gfpflags); if (!s) return NULL ; redo: do { tid = this_cpu_read(s->cpu_slab->tid); c = raw_cpu_ptr(s->cpu_slab); } while (IS_ENABLED(CONFIG_PREEMPTION) && unlikely(tid != READ_ONCE(c->tid))); barrier(); object = c->freelist; page = c->page; if (unlikely(!object || !page || !node_match(page, node))) { object = __slab_alloc(s, gfpflags, node, addr, c); } else { void *next_object = get_freepointer_safe(s, object); if (unlikely(!this_cpu_cmpxchg_double( s->cpu_slab->freelist, s->cpu_slab->tid, object, tid, next_object, next_tid(tid)))) { note_cmpxchg_failure("slab_alloc" , s, tid); goto redo; } prefetch_freepointer(s, next_object); stat(s, ALLOC_FASTPATH); } maybe_wipe_obj_freeptr(s, object); if (unlikely(slab_want_init_on_alloc(gfpflags, s)) && object) memset (kasan_reset_tag(object), 0 , s->object_size); slab_post_alloc_hook(s, objcg, gfpflags, 1 , &object); return object; }
检查参数合法性
检查 kmem_cache_cpu->free_list 和 cpu slab 是否存在
如果都存在,调用 get_freepointer_safe 取下一个空闲对象放入 kmem_cache_cpu->free_list
否则,调用 __slab_alloc 进行慢分配获取对象
根据标志位对对象进行初始化(将 next_free_object 和 data 清零)
返回对象
总的来说就是先尝试快分配,不行就调用 __slab_alloc 进行慢分配,然后根据标志位进行初始化操作,最后返回对象
__slab_alloc为 ___slab_alloc 的封装
mm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr, struct kmem_cache_cpu *c) { void *p; unsigned long flags; local_irq_save(flags); #ifdef CONFIG_PREEMPTION c = this_cpu_ptr(s->cpu_slab); #endif p = ___slab_alloc(s, gfpflags, node, addr, c); local_irq_restore(flags); return p; }
关闭中断,调用 ___slab_alloc 进行实际分配,分配完开启中断
___slab_alloc慢速分配的核心代码
mm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, unsigned long addr, struct kmem_cache_cpu *c) { void *freelist; struct page *page ; stat(s, ALLOC_SLOWPATH); page = c->page; if (!page) { if (unlikely(node != NUMA_NO_NODE && !node_state(node, N_NORMAL_MEMORY))) node = NUMA_NO_NODE; goto new_slab; } redo: if (unlikely(!node_match(page, node))) { if (!node_state(node, N_NORMAL_MEMORY)) { node = NUMA_NO_NODE; goto redo; } else { stat(s, ALLOC_NODE_MISMATCH); deactivate_slab(s, page, c->freelist, c); goto new_slab; } } if (unlikely(!pfmemalloc_match(page, gfpflags))) { deactivate_slab(s, page, c->freelist, c); goto new_slab; } freelist = c->freelist; if (freelist) goto load_freelist; freelist = get_freelist(s, page); if (!freelist) { c->page = NULL ; stat(s, DEACTIVATE_BYPASS); goto new_slab; } stat(s, ALLOC_REFILL); load_freelist: VM_BUG_ON(!c->page->frozen); c->freelist = get_freepointer(s, freelist); c->tid = next_tid(c->tid); return freelist; new_slab: if (slub_percpu_partial(c)) { page = c->page = slub_percpu_partial(c); slub_set_percpu_partial(c, page); stat(s, CPU_PARTIAL_ALLOC); goto redo; } freelist = new_slab_objects(s, gfpflags, node, &c); if (unlikely(!freelist)) { slab_out_of_memory(s, gfpflags, node); return NULL ; } page = c->page; if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags))) goto load_freelist; if (kmem_cache_debug(s) && !alloc_debug_processing(s, page, freelist, addr)) goto new_slab; deactivate_slab(s, page, get_freepointer(s, freelist), c); return freelist; }
对 freelist、cpu slab 和 cpu slab 的 freelist 进行检查,检查是否因为 CPU 迁移或中断出现新的空闲对象,确定是否真的没有空闲对象了,如果还有就跳转到 load_freelist 标签直接取 freelist 的空闲对象即可
如果真没有,就跳转到 new_slab 标签(核心代码)
尝试获取 cpu partial slab,如果有,作为新的 cpu slab,跳转到步骤 1 再做检查
如果没有,调用 new_slab_objects(核心函数) 从 kmem_cache_node 获取 slab
deactivate_slab将 cpu slab 从 kmem_cache_cpu 去掉
mm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 static void deactivate_slab (struct kmem_cache *s, struct page *page, void *freelist, struct kmem_cache_cpu *c) { enum slab_modes { struct kmem_cache_node *n = int lock = 0 ; enum slab_modes l = void *nextfree; int tail = DEACTIVATE_TO_HEAD; struct page new ; struct page old ; if (page->freelist) { stat(s, DEACTIVATE_REMOTE_FREES); tail = DEACTIVATE_TO_TAIL; } while (freelist && (nextfree = get_freepointer(s, freelist))) { void *prior; unsigned long counters; if (freelist_corrupted(s, page, &freelist, nextfree)) break ; do { prior = page->freelist; counters = page->counters; set_freepointer(s, freelist, prior); new.counters = counters; new.inuse--; VM_BUG_ON(!new.frozen); } while (!__cmpxchg_double_slab(s, page, prior, counters, freelist, new.counters, "drain percpu freelist" )); freelist = nextfree; } redo: old.freelist = page->freelist; old.counters = page->counters; VM_BUG_ON(!old.frozen); new.counters = old.counters; if (freelist) { new.inuse--; set_freepointer(s, freelist, old.freelist); new.freelist = freelist; } else new.freelist = old.freelist; new.frozen = 0 ; if (!new.inuse && n->nr_partial >= s->min_partial) m = M_FREE; else if (new.freelist) { m = M_PARTIAL; if (!lock) { lock = 1 ; spin_lock(&n->list_lock); } } else { m = M_FULL; if (kmem_cache_debug_flags(s, SLAB_STORE_USER) && !lock) { lock = 1 ; spin_lock(&n->list_lock); } } if (l != m) { if (l == M_PARTIAL) remove_partial(n, page); else if (l == M_FULL) remove_full(s, n, page); if (m == M_PARTIAL) add_partial(n, page, tail); else if (m == M_FULL) add_full(s, n, page); } l = m; if (!__cmpxchg_double_slab(s, page, old.freelist, old.counters, new.freelist, new.counters, "unfreezing slab" )) goto redo; if (lock) spin_unlock(&n->list_lock); if (m == M_PARTIAL) stat(s, tail); else if (m == M_FULL) stat(s, DEACTIVATE_FULL); else if (m == M_FREE) { stat(s, DEACTIVATE_EMPTY); discard_slab(s, page); stat(s, FREE_SLAB); } c->page = NULL ; c->freelist = NULL ; }
如果 kmem_cache_cpu->freelist 还有空闲对象,就迁移到 slab 上(一般情况下都没有空闲对象了,这一步直接跳过)
解除 slab 与 CPU 的绑定 frozen = 0
根据情况移动该 slab
如果 slab 没有正在使用的对象(全是空闲对象),而且 node slab 足够多了,就调用 discard_slab->free_slab->__free_slab->__free_pages 释放给 Buddy System
如果 slab 还有空闲对象,就插入到 node slab 上
否则说明 slab 没有空闲对象,就插入到 kmem_cache_node->full 链表头上
最后将 kmem_cache_cpu 的 page 和 freelist 置零
new_slab_objectsmm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 static inline void *new_slab_objects (struct kmem_cache *s, gfp_t flags, int node, struct kmem_cache_cpu **pc) { void *freelist; struct kmem_cache_cpu *c = struct page *page ; WARN_ON_ONCE(s->ctor && (flags & __GFP_ZERO)); freelist = get_partial(s, flags, node, c); if (freelist) return freelist; page = new_slab(s, flags, node); if (page) { c = raw_cpu_ptr(s->cpu_slab); if (c->page) flush_slab(s, c); freelist = page->freelist; page->freelist = NULL ; stat(s, ALLOC_SLAB); c->page = page; *pc = c; } return freelist; }
调用 get_partial 从 node slab 中尝试获取空闲对象,如果有则直接返回
调用 new_slab 向 Buddy System 申请新的 slab 作为 cpu slab
返回获取的空闲对象
get_patial & get_partial_node从 kmem_cache_node 获取空闲对象的核心函数
mm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 static void *get_partial (struct kmem_cache *s, gfp_t flags, int node, struct kmem_cache_cpu *c) { void *object; int searchnode = node; if (node == NUMA_NO_NODE) searchnode = numa_mem_id(); object = get_partial_node(s, get_node(s, searchnode), c, flags); if (object || node != NUMA_NO_NODE) return object; return get_any_partial(s, flags, c); } static void *get_partial_node (struct kmem_cache *s, struct kmem_cache_node *n, struct kmem_cache_cpu *c, gfp_t flags) { struct page *page , *page2 ; void *object = NULL ; unsigned int available = 0 ; int objects; if (!n || !n->nr_partial) return NULL ; spin_lock(&n->list_lock); list_for_each_entry_safe(page, page2, &n->partial, slab_list) { void *t; if (!pfmemalloc_match(page, flags)) continue ; t = acquire_slab(s, n, page, object == NULL , &objects); if (!t) continue ; available += objects; if (!object) { c->page = page; stat(s, ALLOC_FROM_PARTIAL); object = t; } else { put_cpu_partial(s, page, 0 ); stat(s, CPU_PARTIAL_NODE); } if (!kmem_cache_has_cpu_partial(s) || available > slub_cpu_partial(s) / 2 ) break ; } spin_unlock(&n->list_lock); return object; }
检查该 node 是否有 node slab,没有则直接返回 NULL
从头到尾遍历 node slab
计算获取的空闲对象总数
如果是第一遍,将该 slab 作为 cpu slab
如果是第二遍以上,将该 slab 放入 cpu partial slab
直到空闲对象总数超过限制的一半
返回 cpu slab 的 freelist
acquire_slabmm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 static inline void *acquire_slab (struct kmem_cache *s, struct kmem_cache_node *n, struct page *page, int mode, int *objects) { void *freelist; unsigned long counters; struct page new ; lockdep_assert_held(&n->list_lock); freelist = page->freelist; counters = page->counters; new.counters = counters; *objects = new.objects - new.inuse; if (mode) { new.inuse = page->objects; new.freelist = NULL ; } else { new.freelist = freelist; } VM_BUG_ON(new.frozen); new.frozen = 1 ; if (!__cmpxchg_double_slab(s, page, freelist, counters, new.freelist, new.counters, "acquire_slab" )) return NULL ; remove_partial(n, page); WARN_ON(!freelist); return freelist; }
计算空闲对象的数量
如果要分配为 cpu slab,设置 inuse 为总对象数量,freelist 设为 NULL
如果要分配为 cpu partial slab,不做变化
冻结,将该 slab 绑定到 CPU
将该 slab 从 node slab 中脱链
返回获取到的 freelist
#todo 对象分配函数调用关系图
kmem_cache_node每个 node 的后备内存池
当 CPU 的独占内存池耗尽后,便会尝试从 kmem_cache_node 中尝试分配
mm/slab.h 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 struct kmem_cache_node { spinlock_t list_lock; #ifdef CONFIG_SLAB #endif #ifdef CONFIG_SLUB unsigned long nr_partial; struct list_head partial ; #ifdef CONFIG_SLUB_DEBUG atomic_long_t nr_slabs; atomic_long_t total_objects; struct list_head full ; #endif #endif };
list_lock:保护 partial 和 full 链表的锁partial:双向链表,连接有部分空闲对象的 slab,这里简称为 node slabnr_partial:partial slab 的数量nr_slabs:总的 slab 数量total_objects:总的对象数量full:双向链表,连内存完全耗尽的 slab,一般用不到
#todo kmem_cache_node 与 slab 的联系
对象释放 do_slab_free上层接口最终都会调用 do_slab_free 函数来完成内存释放
struct kmem_cache *s:当前 kmem_cachestruct page *page:被释放的对象所在的 pagevoid *head:被释放的第一个对象void *tail:被释放的最后一个对象int cnt:被释放的对象的个数unsigned long addr:开启 SLAB_DEBUG_FLAGS 后使用,一般不会使用
mm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 static __always_inline void do_slab_free (struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) { void *tail_obj = tail ? : head; struct kmem_cache_cpu *c ; unsigned long tid; memcg_slab_free_hook(s, &head, 1 ); redo: do { tid = this_cpu_read(s->cpu_slab->tid); c = raw_cpu_ptr(s->cpu_slab); } while (IS_ENABLED(CONFIG_PREEMPTION) && unlikely(tid != READ_ONCE(c->tid))); barrier(); if (likely(page == c->page)) { void **freelist = READ_ONCE(c->freelist); set_freepointer(s, tail_obj, freelist); if (unlikely(!this_cpu_cmpxchg_double( s->cpu_slab->freelist, s->cpu_slab->tid, freelist, tid, head, next_tid(tid)))) { note_cmpxchg_failure("slab_free" , s, tid); goto redo; } stat(s, FREE_FASTPATH); } else __slab_free(s, page, head, tail_obj, cnt, addr); }
判断释放的对象是否属于 cpu slab
如果属于,进入快释放,将释放对象插入 kmem_cache_cpu->freelist 链表头
如果不属于,调用 __slab_free 函数进入慢释放
__slab_freemm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 static void __slab_free(struct kmem_cache *s, struct page *page, void *head, void *tail, int cnt, unsigned long addr) { void *prior; int was_frozen; struct page new ; unsigned long counters; struct kmem_cache_node *n =NULL ; unsigned long flags; stat(s, FREE_SLOWPATH); if (kmem_cache_debug(s) && !free_debug_processing(s, page, head, tail, cnt, addr)) return ; do { if (unlikely(n)) { spin_unlock_irqrestore(&n->list_lock, flags); n = NULL ; } prior = page->freelist; counters = page->counters; set_freepointer(s, tail, prior); new.counters = counters; was_frozen = new.frozen; new.inuse -= cnt; if ((!new.inuse || !prior) && !was_frozen) { if (kmem_cache_has_cpu_partial(s) && !prior) { new.frozen = 1 ; } else { n = get_node(s, page_to_nid(page)); spin_lock_irqsave(&n->list_lock, flags); } } } while (!cmpxchg_double_slab(s, page, prior, counters, head, new.counters, "__slab_free" )); if (likely(!n)) { if (likely(was_frozen)) { stat(s, FREE_FROZEN); } else if (new.frozen) { put_cpu_partial(s, page, 1 ); stat(s, CPU_PARTIAL_FREE); } return ; } if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) goto slab_empty; if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) { remove_full(s, n, page); add_partial(n, page, DEACTIVATE_TO_TAIL); stat(s, FREE_ADD_PARTIAL); } spin_unlock_irqrestore(&n->list_lock, flags); return ; slab_empty: if (prior) { remove_partial(n, page); stat(s, FREE_REMOVE_PARTIAL); } else { remove_full(s, n, page); } spin_unlock_irqrestore(&n->list_lock, flags); stat(s, FREE_SLAB); discard_slab(s, page); }
将被释放对象插入 page->freelist 中
计算释放后正在使用的对象数量
如果该 slab 释放前为 full slab,则绑定到 CPU,放入 cpu partial slab 中
如果该 slab 释放前为 full slab,且没有开启 CONFIG_SLUB_CPU_PARTIAL,则放入 node slab
如果该 slab 释放后为 empty slab 且 node slab 足够多,则释放给 Buddy System
其他情况表明该 slab 已经位于 cpu partial slab 或 node slab 中,保持不变
总结
分配:
首先从 kmem_cache_cpu 上的 cpu slab 取对象,若有则直接返回
若 cpu slab 已经无空闲对象了,该 slab 会被加入到 kmem_cache_node->full 链表
尝试从 kmem_cache_cpu 上的 cpu partial slab 链表上取 slab,并作为 cpu slab
若 cpu partial slab 链表为空,则从 kmem_cache_node 上的 node slab 取若干个 slab 放到 kmem_cache_cpu 的 cpu slab 和 cpu partial slab 上,然后再取出空闲对象返回
若 node slab 链表也空了,那就向 Buddy Bystem 请求分配新的页面,划分为多个 object 之后再给到 kmem_cache_cpu,取空闲对象返回上层调用
释放:
若被释放 object 属于 kmem_cache_cpu 的 slab,直接使用头插法插入当前 CPU slub 的 freelist
若被释放 object 属于 kmem_cache_node 的 node slab,直接使用头插法插入对应 slub 的 freelist
若被释放 object 属于 kmem_cache_node 的 full slab,则其会成为对应 slab 的 freelist 头节点,且该 slab 会从 full 链表迁移到 cpu partial slab(优先) 或 node slab
Kmalloc kmalloc 实际上属于 Slab 的最上层接口函数,但是它在使用时会根据情况直接调用 Buddy System 函数,因此单独拿出来写
kmallockmalloc 是内核中常用的分配内存的函数
size_t size:申请的内存大小gfp_t:分配标志位
include/linux/slab.h 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static __always_inline void *kmalloc (size_t size, gfp_t flags) { if (__builtin_constant_p(size)) { unsigned int index; if (size > KMALLOC_MAX_CACHE_SIZE) return kmalloc_large(size, flags); index = kmalloc_index(size); if (!index) return ZERO_SIZE_PTR; return kmem_cache_alloc_trace( kmalloc_caches[kmalloc_type(flags)][index], flags, size); } return __kmalloc(size, flags); }
如果申请大小在编译时已知
如果大小大于 kmem_cache 中对象的最大大小,则调用 kmalloc_large 直接向 Buddy System 申请整个页面
否则,调用 kmalloc_index 计算对应大小的下标
调用 kmalloc_type 获取对应的 kmem_cache 类型
通过来类型和下标在 kmalloc_caches 中获取对应的 kmem_cache
调用 kmem_cache_alloc_trace 申请内存
否则调用 __kmalloc 动态分配内存
__kmallocmm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void *__kmalloc(size_t size, gfp_t flags){ struct kmem_cache *s ; void *ret; if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) return kmalloc_large(size, flags); s = kmalloc_slab(size, flags); if (unlikely(ZERO_OR_NULL_PTR(s))) return s; ret = slab_alloc(s, flags, _RET_IP_); trace_kmalloc(_RET_IP_, ret, size, s->size, flags); ret = kasan_kmalloc(s, ret, size, flags); return ret; }
如果大小大于 kmem_cache 中对象的最大大小,则调用 kmalloc_large 直接向 Buddy System 申请整个页面
否则,调用 kmalloc_slab 获取对应的 kmem_cache
调用 slab_alloc->slab_alloc_node 进行内存分配
kfree
mm/slub.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 void kfree (const void *x) { struct page *page ; void *object = (void *)x; trace_kfree(_RET_IP_, x); if (unlikely(ZERO_OR_NULL_PTR(x))) return ; page = virt_to_head_page(x); if (unlikely(!PageSlab(page))) { unsigned int order = compound_order(page); BUG_ON(!PageCompound(page)); kfree_hook(object); mod_node_page_state(page_pgdat(page), NR_SLAB_UNRECLAIMABLE_B, -(PAGE_SIZE << order)); __free_pages(page, order); return ; } slab_free(page->slab_cache, page, object, NULL , 1 , _RET_IP_); }
将被释放的内存首地址转换为对应页面的第一个 page 结构体地址
检查该页面是否为一张 slab
若不是,则获取页面的阶,释放给 Buddy System
若是,则调用 slab_free->do_slab_free 进行内存释放
参考链接 【OS.0x02】Linux 内核内存管理I - 页、区、节点
【OS.0x03】Linux内核内存管理II - Buddy System
【OS.0x04】Linux Kernel 内存管理浅析 III - Slub Allocator
linux内存管理(一)-内存管理架构