void *malloc(size_t n) { if (size_overflows(n)) return0; structmeta *g; uint32_t mask, first; // sizeclass int sc; int idx; int ctr;
// mmap 分配 // #define MMAP_THRESHOLD 131052 if (n >= MMAP_THRESHOLD) { size_t needed = n + IB + UNIT; void *p = mmap(0, needed, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0); if (p==MAP_FAILED) return0; wrlock(); step_seq(); g = alloc_meta(); if (!g) { unlock(); munmap(p, needed); return0; } g->mem = p; g->mem->meta = g; g->last_idx = 0; g->freeable = 1; g->sizeclass = 63; g->maplen = (needed+4095)/4096; g->avail_mask = g->freed_mask = 0; // use a global counter to cycle offset in // individually-mmapped allocations. ctx.mmap_counter++; idx = 0; goto success; }
// 根据 n 取 size_classes 对应大小的下标 sc = size_to_class(n);
rdlock(); /* 寻找合适的 meta */ // 获取对应大小的 meta g = ctx.active[sc];
// use coarse size classes initially when there are not yet // any groups of desired size. this allows counts of 2 or 3 // to be allocated at first rather than having to start with // 7 or 5, the min counts for even size classes. // 如果没有对应的 meta,且 4 <= sc < 32 且 sc !=6 且 sc 为偶数 且对应大小的所有 chunk 数量为 0 if (!g && sc>=4 && sc<32 && sc!=6 && !(sc&1) && !ctx.usage_by_class[sc]) { // 使用更大一点(sc+1)的 meta size_t usage = ctx.usage_by_class[sc|1]; // if a new group may be allocated, count it toward // usage in deciding if we can use coarse class. // 如果 sc+1 对应的 meta 也不存在或存在但没有可用的 chunk 则 usage+3 if (!ctx.active[sc|1] || (!ctx.active[sc|1]->avail_mask && !ctx.active[sc|1]->freed_mask)) usage += 3; // 如果 usage <= 12 则 sc+1 if (usage <= 12) sc |= 1; g = ctx.active[sc]; } /* end */
staticuint32_ttry_avail(struct meta **pm) { structmeta *m = *pm; uint32_t first; if (!m) return0; uint32_t mask = m->avail_mask; // 若没有可分配的 chunk if (!mask) { if (!m) return0; if (!m->freed_mask) { /* 且也没有 freed chunk,即 group 中的 chunk 都是 inuse 则将该 meta 从 ctx.active[sc] 和 双向链表中移除 */ dequeue(pm, m); m = *pm; if (!m) return0; } else { // 优先使用下一个 meta 的 freed_chunk m = m->next; *pm = m; }
mask = m->freed_mask;
// skip fully-free group unless it's the only one // or it's a permanently non-freeable group // 跳过所有 chunk 都是 freed_chunk 且可 free 的 meta,一般不会出现这个情况 if (mask == (2u<<m->last_idx)-1 && m->freeable) { m = m->next; *pm = m; mask = m->freed_mask; }
// activate more slots in a not-fully-active group // if needed, but only as a last resort. prefer using // any other group with free slots. this avoids // touching & dirtying as-yet-unused pages. /* 总结起来就是,如果第一个 meta 的 chunk 都是 inuse, 且第二个 meta 的 freed_chunk 使用完了,才进入下面的操作 可能是什么特殊情况,正常不会出现这个情况*/ if (!(mask & ((2u<<m->mem->active_idx)-1))) { if (m->next != m) { m = m->next; *pm = m; } else { int cnt = m->mem->active_idx + 2; int size = size_classes[m->sizeclass]*UNIT; int span = UNIT + size*cnt; // activate up to next 4k boundary while ((span^(span+size-1)) < 4096) { cnt++; span += size; } if (cnt > m->last_idx+1) cnt = m->last_idx+1; m->mem->active_idx = cnt-1; } } // 将 freed_mask 转为 avail_mask mask = activate_group(m); assert(mask); decay_bounces(m->sizeclass); } first = mask&-mask; m->avail_mask = mask-first; return first; }
若 active 第一个 meta 的 chunk 都是 inuse,则将此 meta 从 active 和 链表中移出
将 active 第一个 meta 设置为下一个 meta
将其 freed_mask 转为 avail_mask 使用
取 avail_mask 中 idx 最小的 chunk
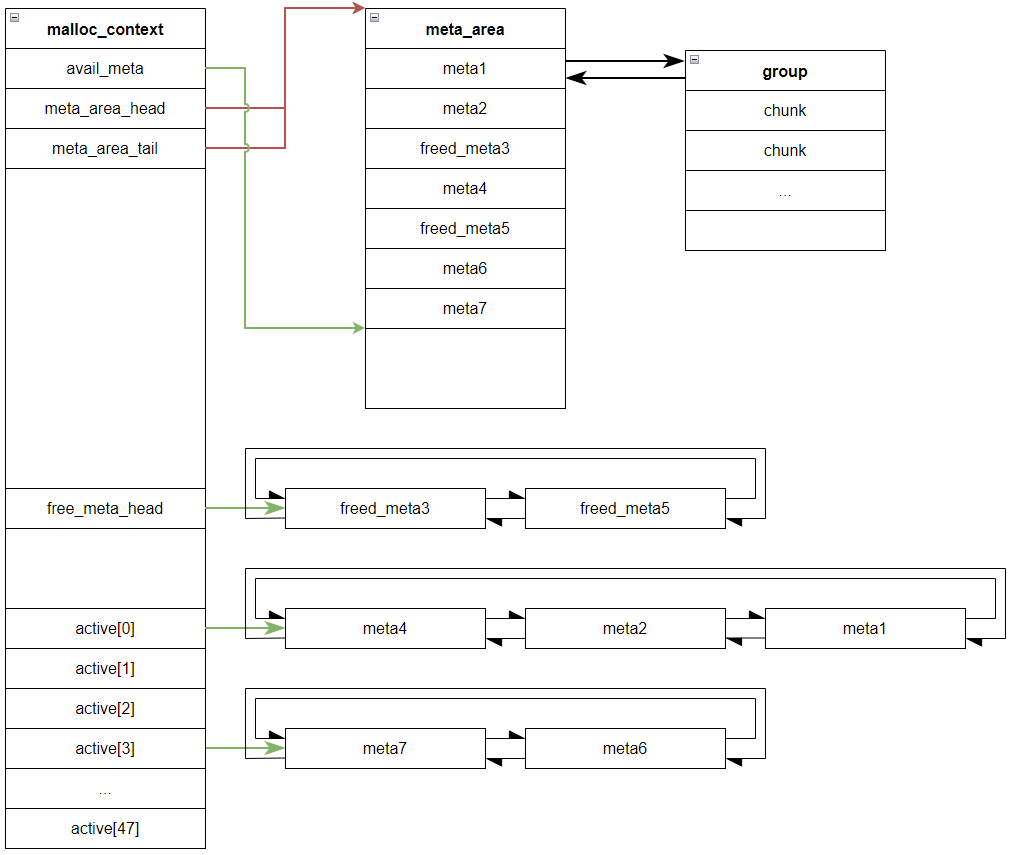
queue
./src/malloc/mallocng/meta.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14
staticinlinevoidqueue(struct meta **phead, struct meta *m) { assert(!m->next); assert(!m->prev); if (*phead) { structmeta *head = *phead; m->next = head; m->prev = head->prev; m->next->prev = m->prev->next = m; } else { m->prev = m->next = m; *phead = m; } }
dequeue
./src/malloc/mallocng/meta.h
1 2 3 4 5 6 7 8 9 10 11
staticinlinevoiddequeue(struct meta **phead, struct meta *m) { if (m->next != m) { m->prev->next = m->next; m->next->prev = m->prev; if (*phead == m) *phead = m->next; } else { *phead = 0; } m->prev = m->next = 0; }
staticstruct meta *alloc_group(int sc, size_t req) { size_t size = UNIT*size_classes[sc]; int i = 0, cnt; unsignedchar *p; // 优先寻找 freed_meta,将其从 ctx.free_meta_head 移除 // 若没有就从 meta_area 中按地址从低到高顺序取一个 // 如果 meta_area 满了,则再申请一个 meta_area // 会将 meta 的 prev,next 置零 structmeta *m = alloc_meta(); if (!m) return0; size_t usage = ctx.usage_by_class[sc]; size_t pagesize = PGSZ; int active_idx; /* 设置 cnt,也就是 group 能容纳 chunk 最大数量 */ if (sc < 9) { while (i<2 && 4*small_cnt_tab[sc][i] > usage) i++; cnt = small_cnt_tab[sc][i]; } else { // lookup max number of slots fitting in power-of-two size // from a table, along with number of factors of two we // can divide out without a remainder or reaching 1. cnt = med_cnt_tab[sc&3];
// reduce cnt to avoid excessive eagar allocation. while (!(cnt&1) && 4*cnt > usage) cnt >>= 1;
// data structures don't support groups whose slot offsets // in units don't fit in 16 bits. while (size*cnt >= 65536*UNIT) cnt >>= 1; } /* end */
// If we selected a count of 1 above but it's not sufficient to use // mmap, increase to 2. Then it might be; if not it will nest. if (cnt==1 && size*cnt+UNIT <= pagesize/2) cnt = 2;
// All choices of size*cnt are "just below" a power of two, so anything // larger than half the page size should be allocated as whole pages. if (size*cnt+UNIT > pagesize/2) { // check/update bounce counter to start/increase retention // of freed maps, and inhibit use of low-count, odd-size // small mappings and single-slot groups if activated. int nosmall = is_bouncing(sc); account_bounce(sc); step_seq();
// since the following count reduction opportunities have // an absolute memory usage cost, don't overdo them. count // coarse usage as part of usage. if (!(sc&1) && sc<32) usage += ctx.usage_by_class[sc+1];
// try to drop to a lower count if the one found above // increases usage by more than 25%. these reduced counts // roughly fill an integral number of pages, just not a // power of two, limiting amount of unusable space. if (4*cnt > usage && !nosmall) { if (0); elseif ((sc&3)==1 && size*cnt>8*pagesize) cnt = 2; elseif ((sc&3)==2 && size*cnt>4*pagesize) cnt = 3; elseif ((sc&3)==0 && size*cnt>8*pagesize) cnt = 3; elseif ((sc&3)==0 && size*cnt>2*pagesize) cnt = 5; } size_t needed = size*cnt + UNIT; needed += -needed & (pagesize-1);
// produce an individually-mmapped allocation if usage is low, // bounce counter hasn't triggered, and either it saves memory // or it avoids eagar slot allocation without wasting too much. if (!nosmall && cnt<=7) { req += IB + UNIT; req += -req & (pagesize-1); if (req<size+UNIT || (req>=4*pagesize && 2*cnt>usage)) { cnt = 1; needed = req; } }
p = mmap(0, needed, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0); if (p==MAP_FAILED) { free_meta(m); return0; } m->maplen = needed>>12; ctx.mmap_counter++; active_idx = (4096-UNIT)/size-1; if (active_idx > cnt-1) active_idx = cnt-1; if (active_idx < 0) active_idx = 0; } else { int j = size_to_class(UNIT+cnt*size-IB); // 从大 group 中申请小 group,大 group 的 chunk 作为整个小 group,是一个递归过程 int idx = alloc_slot(j, UNIT+cnt*size-IB); if (idx < 0) { free_meta(m); return0; } structmeta *g = ctx.active[j]; p = enframe(g, idx, UNIT*size_classes[j]-IB, ctx.mmap_counter); m->maplen = 0; p[-3] = (p[-3]&31) | (6<<5); for (int i=0; i<=cnt; i++) p[UNIT+i*size-4] = 0; active_idx = cnt-1; } // 增加可用 chunk 个数 ctx.usage_by_class[sc] += cnt; // 初始化 meta 和 group m->avail_mask = (2u<<active_idx)-1; m->freed_mask = (2u<<(cnt-1))-1 - m->avail_mask; m->mem = (void *)p; m->mem->meta = m; // group 的 active_idx 和 meta 的 last_idx 一般是相等的,为 cnt-1 m->mem->active_idx = active_idx; m->last_idx = cnt-1; m->freeable = 1; m->sizeclass = sc; return m; }
structmeta *g = get_meta(p); int idx = get_slot_index(p); size_t stride = get_stride(g); unsignedchar *start = g->mem->storage + stride*idx; unsignedchar *end = start + stride - IB; // 检查 reserved get_nominal_size(p, end); uint32_t self = 1u<<idx, all = (2u<<g->last_idx)-1; // idx 和 reserved 置 0xff,offset 置 0 ((unsignedchar *)p)[-3] = 255; // invalidate offset to group header, and cycle offset of // used region within slot if current offset is zero. *(uint16_t *)((char *)p-2) = 0;
// release any whole pages contained in the slot to be freed // unless it's a single-slot group that will be unmapped. if (((uintptr_t)(start-1) ^ (uintptr_t)end) >= 2*PGSZ && g->last_idx) { unsignedchar *base = start + (-(uintptr_t)start & (PGSZ-1)); size_t len = (end-base) & -PGSZ; if (len) madvise(base, len, MADV_FREE); }
// atomic free without locking if this is neither first or last slot for (;;) { uint32_t freed = g->freed_mask; uint32_t avail = g->avail_mask; uint32_t mask = freed | avail; assert(!(mask&self)); // 如果没有 freed_chunk 或者都是 unuse_chunk,则跳出循环 if (!freed || mask+self==all) break; if (!MT) g->freed_mask = freed+self; elseif (a_cas(&g->freed_mask, freed, freed+self)!=freed) continue; return; }
staticstruct mapinfo nontrivial_free(struct meta *g, int i) { uint32_t self = 1u<<i; int sc = g->sizeclass; uint32_t mask = g->freed_mask | g->avail_mask;
// 一般情况,只要所有 chunk 都是 unuse,就会 free meta 和 group if (mask+self == (2u<<g->last_idx)-1 && okay_to_free(g)) { // any multi-slot group is necessarily on an active list // here, but single-slot groups might or might not be. if (g->next) { assert(sc < 48); int activate_new = (ctx.active[sc]==g); dequeue(&ctx.active[sc], g); // 将下一个 meta 的 freed_chunk 转为 avail_chunk if (activate_new && ctx.active[sc]) activate_group(ctx.active[sc]); } return free_group(g); } elseif (!mask) { // 如果 meta 不在 active 里,则放入 actvie 中 assert(sc < 48); // might still be active if there were no allocations // after last available slot was taken. if (ctx.active[sc] != g) { queue(&ctx.active[sc], g); } } // g->freed_mask = g->free_mask & self a_or(&g->freed_mask, self); return (struct mapinfo){ 0 }; }